set.seed(123) # for reproducibility
library(mice) # for imputation
library(miceadds) # for imputation
library(ggmice) # for visualization
library(ggplot2) # for visualization
library(dplyr) # for data wrangling
library(lme4) # for multilevel modeling
library(broom) # for tidying model output
library(broom.mixed) # for tidying model output
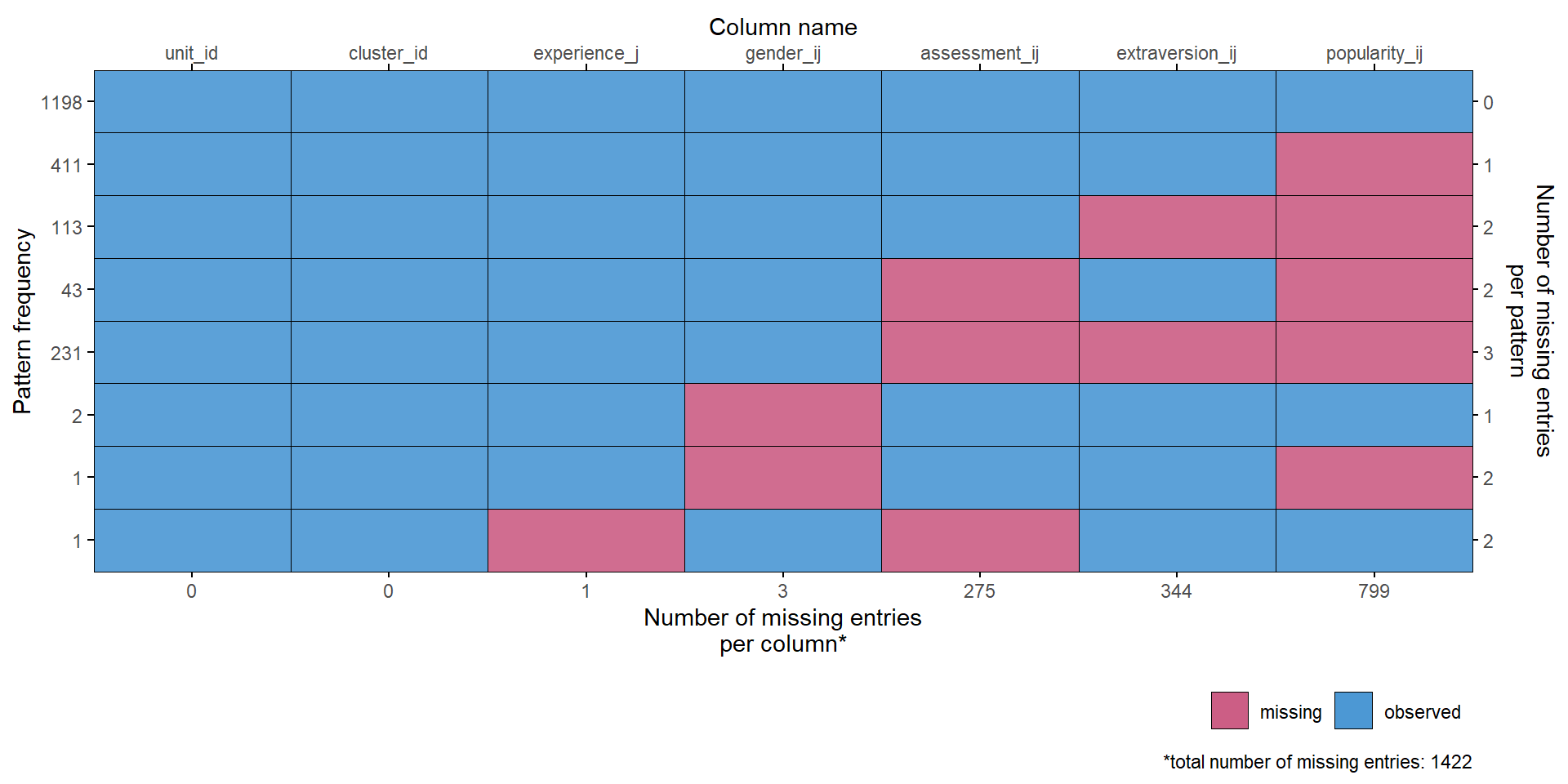
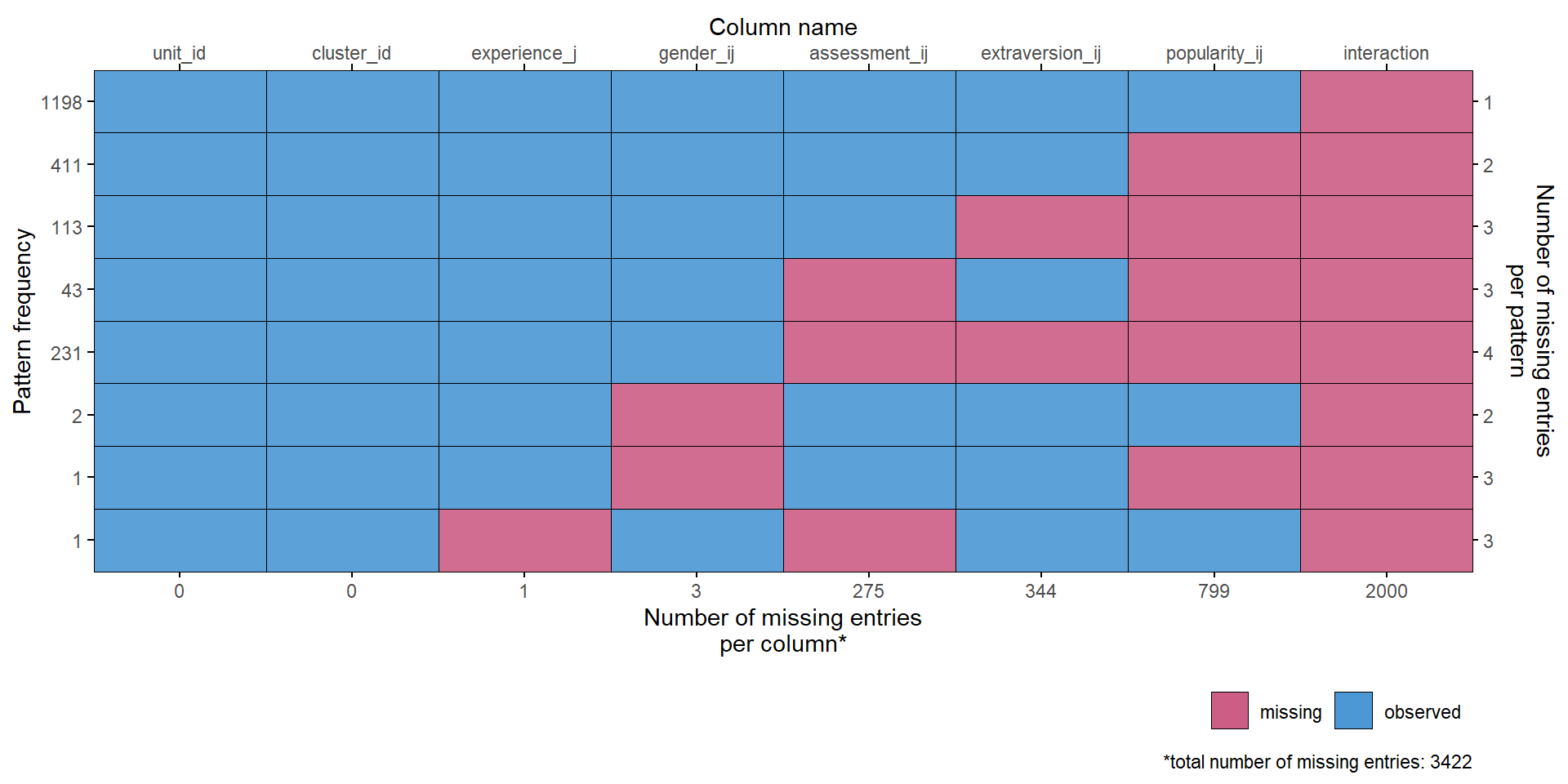
str(dat)'data.frame': 2000 obs. of 7 variables:
$ unit_id : num 1 2 3 4 5 6 7 8 9 10 ...
$ cluster_id : num 1 1 1 1 1 1 1 1 1 1 ...
$ popularity_ij : num 6.3 4.9 5.3 4.7 6 4.7 5.9 NA 5.2 NA ...
$ gender_ij : num 2 1 2 2 2 1 1 1 1 1 ...
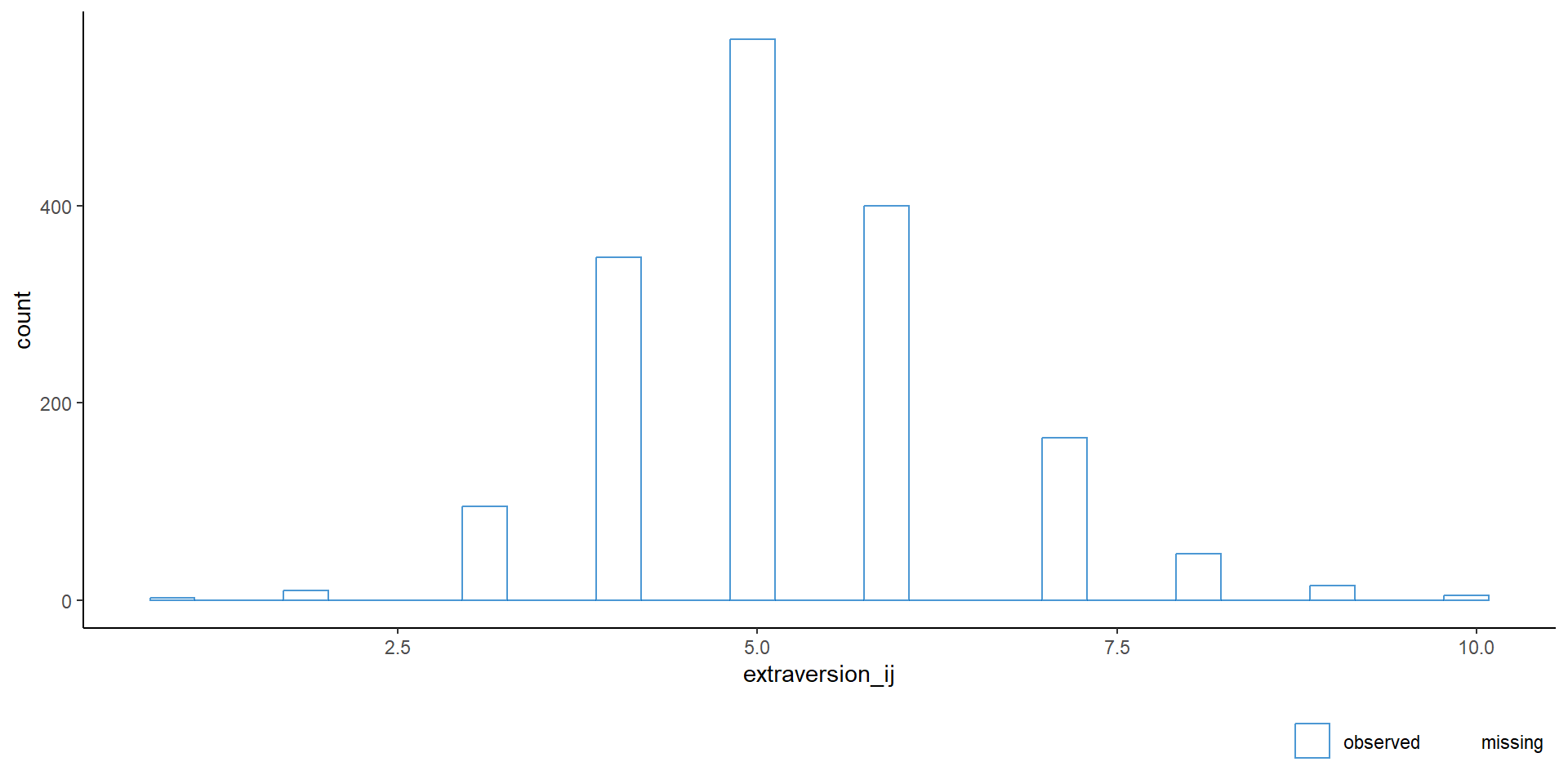
$ extraversion_ij: num 5 7 4 3 5 4 5 NA 5 5 ...
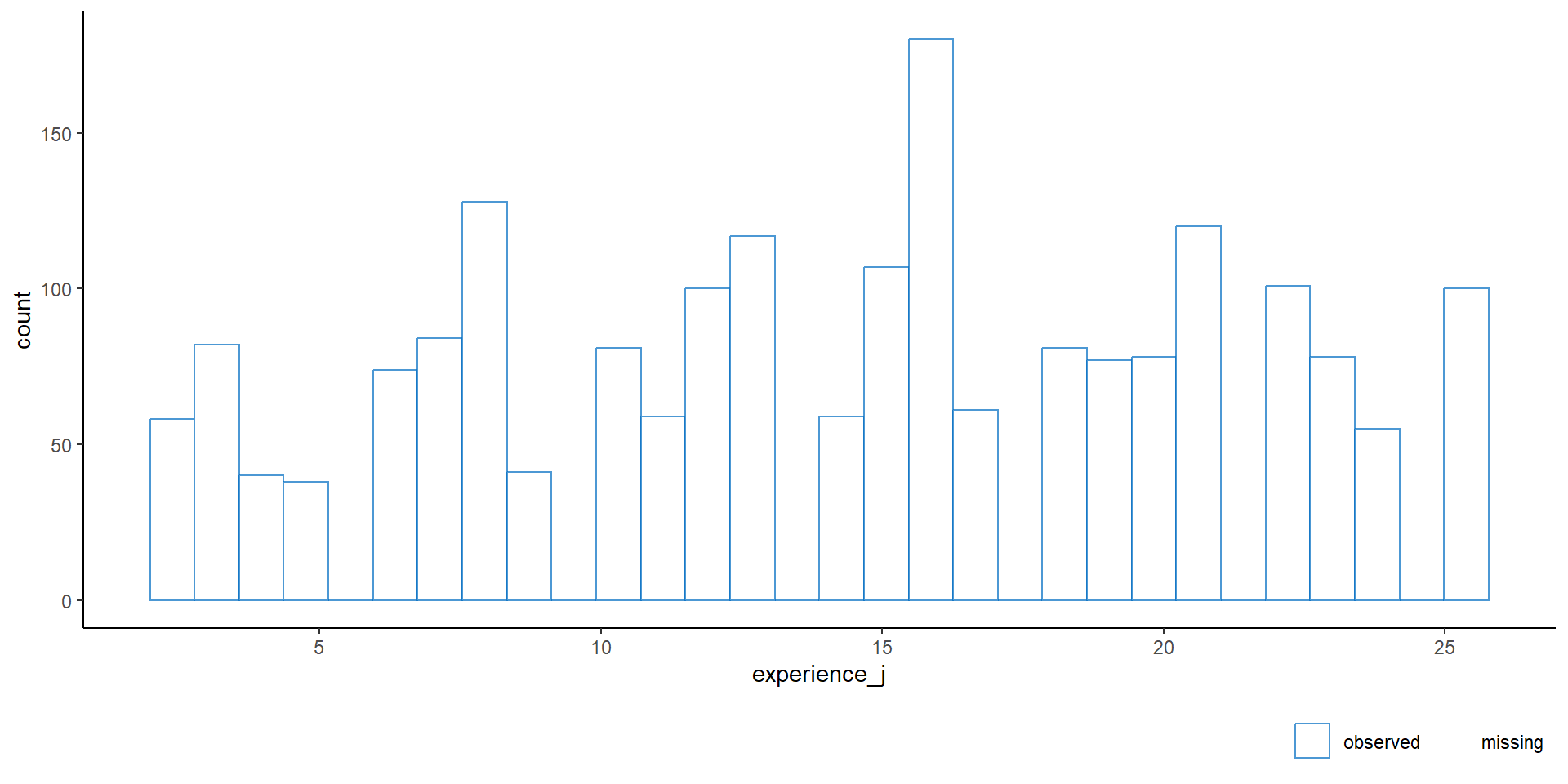
$ experience_j : num 24 NA 24 24 24 24 24 24 24 24 ...
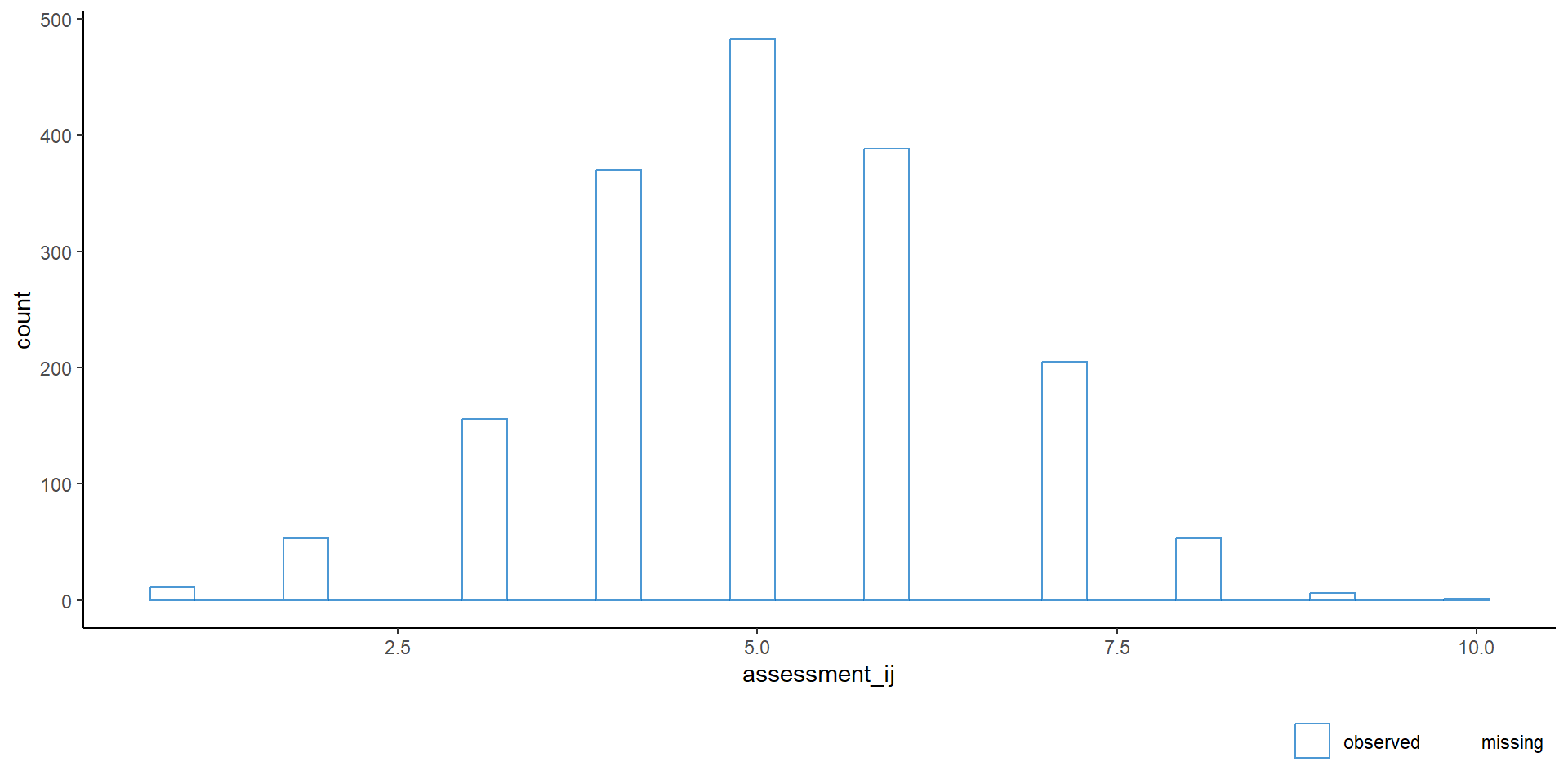
$ assessment_ij : num 6 NA 6 5 6 5 5 NA 5 3 ...